



 在线咨询
在线咨询 400-098-7607
400-098-7607 在线咨询
在线咨询 申请试用
申请试用












 关于安在
关于安在
 新闻动态
新闻动态
 品牌标志
品牌标志
 联系我们
联系我们
 工作机会
工作机会
























 22 min
22 min  返回文章列表
返回文章列表
在Ping32的11月份的更新中(3.7.59),我们最重要的一项工作是,在OneDLP数据防泄漏子系统中重新设计了新的数据分类规则库以及重构了敏感内容识别引擎。以及在此基础上,将若干功能与敏感内容识别逻辑进行整合。
数据分类规则库
数据分类是指,将散落在终端各处以及实时产生的数据进行归类,属性涵盖:数据类别、名称、敏感级别等。对于数据防泄漏产品来讲,最核心的一个功能就是对存在数据泄漏风险的行为进行阻断、告警。这里面的一个关键是,如何识别存在数据泄漏风险的行为?我们不妨想象一下职场中常见的一些行为:
1、将一些公司内部文档拷贝到了私人U盘或网盘;
2、在互联网平台上(微博、知乎等)发布了一些不合规的内容、言论;
3、发送出去的电子邮件正文包含了一些敏感的内容;
4、通过微信等即时通讯软件,发送了涉密的内容以及文档;
5、通过打印机,打印了一份涉密文档;
……
对于数据防泄漏产品来说,识别、捕获以上行为所用到的技术手段不尽相同。但是这里面却有一个共同点:即对捕获到的数据进行风险分析,对数据进行分析、归类的方法可以是基于机器学习技术的某些模型进行自动归类,也可以是依靠人工录入的规则引擎进行分类。下面我将介绍,Ping32数据防泄漏3.7.59的数据分类功能。
上面我们谈到了数据分类的基本属性:数据类别、名称、敏感级别、描述等。这些都非常好理解。此外,分类的对象也是一个重要的概念。我们将数据分为了两个类别,一种是散落在终端各处(本地磁盘、网络存储、可移动磁盘等)的非结构化数据,即文件。另一种是存在于内存中,没有落地的数据,我们泛称为数据,比如:微博、知乎待发布的内容、正在编辑待发送的电子邮件、输入打印机任务队列的数据流、剪切板等。因此我们支持对每个数据分类规则设定生效范围,可以应用到文件规则或是数据规则。对于应用到文件类型的规则,我们还可以进一步根据文件的属性进行筛选,比如:文件大小、文件的文件系统属性、所在位置、文件类型等。我们的决策逻辑会优先分析规则的基础属性,当匹配成功后,才会最终去分析里面的数据规则。
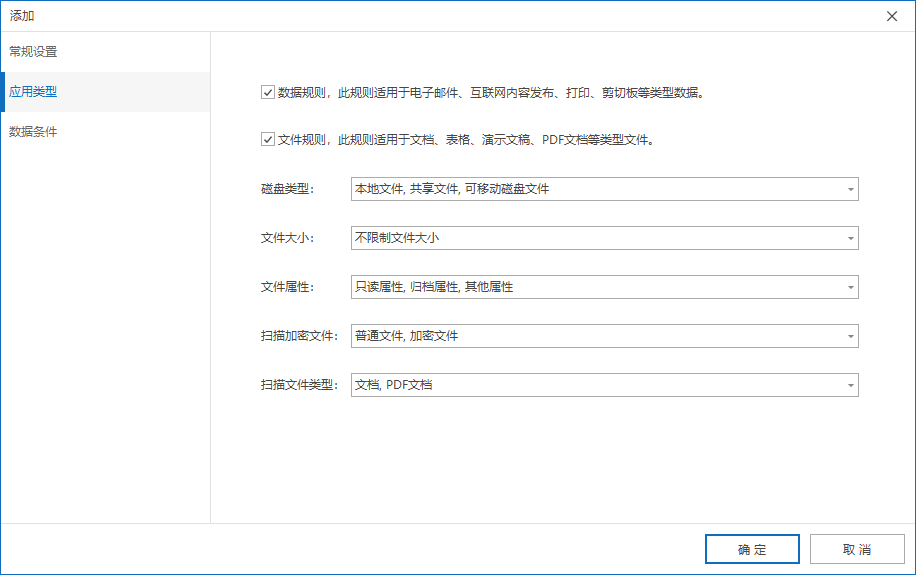
数据规则基础属性
最后,我们再聊聊数据分类中的数据条件。最简单的数据条件就是,要检测数据中是否包含指定的关键字。但是,只检查某个关键字往往很难精准地对这份数据进行定义、归类。因此再次基础上,我们扩展了数据条件的定义规则。目前,我们支持两种类型的特征值,关键字和正则表达式,每种特征都支持设置至少达到指定的命中次数才生效。此外,我们也支持若干个特征条件进行组合。
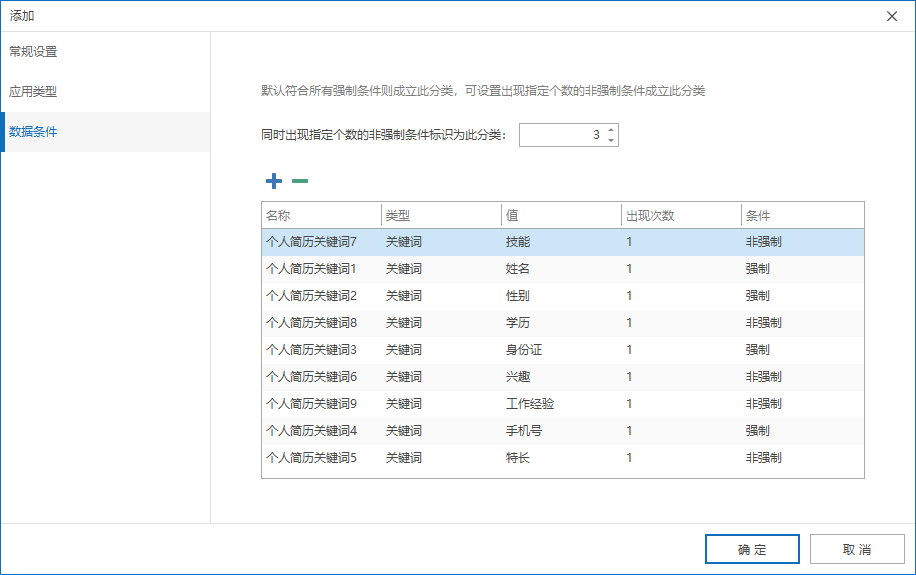
数据条件
敏感内容识别引擎
数据分类规则设计完成后,另一个重点是敏感内容识别引擎的设计。我们接着回到上文提到的几个数据泄密的场景,在这些场景中,如果想要避免数据泄漏,要解决的核心问题是:快速、精准地识别相关文档是否包含敏感内容。精准很好理解,即文档能根据数据分类规则,精准地被分类。这里面我们要谈一下“快速”这个问题。
谈这个话题前,我们先了解一些前置知识,相信大家都不陌生。我们使用Windows时经常会发现一个现象,某个软件“卡住”了,然后窗口内容变成了毛玻璃效果,同时窗口标题出现了未响应字样。站在Windows窗口机制的角度来描述这个现象是,由于窗口的消息循环处理某个事件耗时过长,然后窗口管理器(DWM)会创建一个新的窗口,类名是Ghost,覆盖在原窗口上。聊这个是因为,有时我们对于一些文件的外发行为进行管控和审计,代码是运行在窗口消息循环的上下文,如果这个分析耗时过长,则容易造成窗口卡住的效果,进而带来了糟糕的用户体验。在引入敏感内容识别后,此类问题往往更容易发生。所以,我们过去的一个工作重点是,如何快速进行敏感内容识别。
在这个版本中,我们引入了一项叫“智能缓存”的技术。顾名思义,我们会根据用户的使用习惯,智能地预加载某些文档到内存中,如果一旦需要在窗口消息循环的上下文中对文档进行敏感内容检测,这时并不会从硬盘中读取数据,然后分析(这个过程可能很慢,取决于磁盘类型和文件大小等),而是从预加载的缓存中进行分析。整个流程可以极大地加速文件的分析。
敏感内容扫描策略
最后,基于我们上述技术核心,我们在这个版本中加入了一个敏感内容扫描策略。通过敏感内容扫描策略,你可以扫描指定终端上的文档,分析是否包含指定的敏感数据类别。
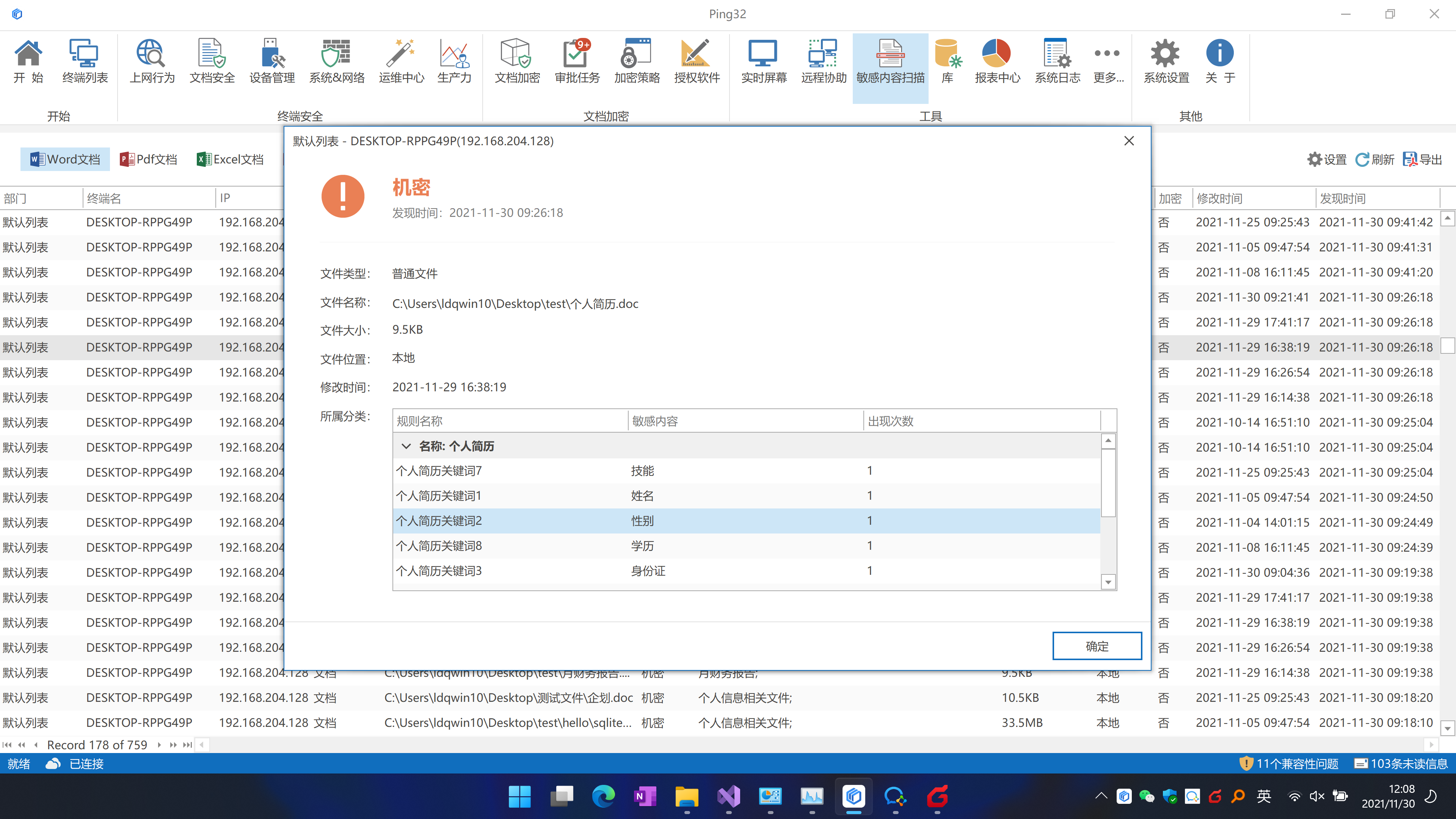
Ping32敏感内容识别

